Scaling Unsplash with a small team
Handling the scale of the leading image service with a small team

One of the most fun things about building Unsplash is the sheer size, scale, and popularity of the product.
On an average day, our API handles 10M+ requests from unsplash.com and thousands of 3rd party applications, our data pipeline processes millions of events, our feeds add 60M updates, and we serve 60 million images.
At the same time, our team is relatively small: 2 designers, 3 frontends, 3 backends, and 1 data engineer. No one is tasked with devops and everyone spends the majority of their time on experimentation and new feature development to fuel growth.
While we’ve accomplished a lot with Unsplash, we’re still at the very beginning of its journey as a product and a business. We still have a lot to prove, meaning we need the entire team focused and solving the problems unique to Unsplash, and not the ones that every company shares, like deployment, network security, infrastructure, dependency management, etc.
Over the past 3 years, we’ve developed a set of principles that allow us to focus on growth and away from scaling challenges. Unfortunately, for those of you looking for a magic bullet, there is none: just common sense and a set of principles we’ve liberally borrowed from others.
1. Build boring, obvious solutions
A.K.A. Be Pragmatic™
Before reaching to introduce a new tool, whether it’s a new database (RethinkDB, RocksDB, etc.), a new pattern (“functional everything!”), or a new architecture (“microservices to the rescue!”), exhaust the obvious options first.
On the backend, there are very few problems that can’t be made “good enough” using standard workhorse tools and a few tried-and-trued patterns, like caching, batching, asynchronous operations, and pre-request aggregation.
2. Focus on solving user problems, not technology problems
Unsplash is a product company, not a technology company. We were given a lot of money by investors specifically so that we can focus on solving a product and market problem, not trying to eek out a 3% improvement in operating costs for our application of a common technology.
Instead we focus our time on connecting pre-built technologies in a way that solves our user’s problems and expands Unsplash’s community. These are the parts unique to Unsplash and if we succeed in building something unique and of value, we can tackle optimizations and heavy customization at a later date, where those 3% optimizations may be the main sources of growth left.
This can be confusing to prospective teammates, as they’ll hear about Unsplash’s ‘scale’ and small team, usage of imagery and AI, and future features, only to realize that we use a lot of off the shelf technologies, services, and frameworks, while paying a small premium to punt the in-house development of these technologies down the line to our future teammates.
Deployment pipelines, server configuration, system dependencies, data processing, data analysis, image processing, and personalization (to name a few) are examples of areas we chose not to focus on investing our engineering resources in, choosing instead 3rd-party services to handle each of them.
3. Throw money at technical problems
The flip side of not focusing on a technology problem is paying a premium for access to a pre-built technology or 3rd-party service.
It’s become a bit of a joke within the team that my first response for any problem will be ‘Have you tried throwing money at it?’. But it’s not a joke and it’s one of my favourite approaches to problem solving.
Optimizing the costs associated with infrastructure and technology is such a common problem with simple, repeatable solutions, that no investor-backed product company should concern themselves with it until they feel that growth of a top-line metric is no longer their number one priority.
Throwing money at a technological problem frees our team up to focus on the non-repeatable, hard problems, like figuring out how to collectively grow a user base 40% in a quarter.
So these are three fairly simple, but abstract principles we follow.
How does that actually look in practice?
If you look at Unsplash’s architecture, you can see that we have a very simple—almost boring (at least by 2017’s standards)—setup.
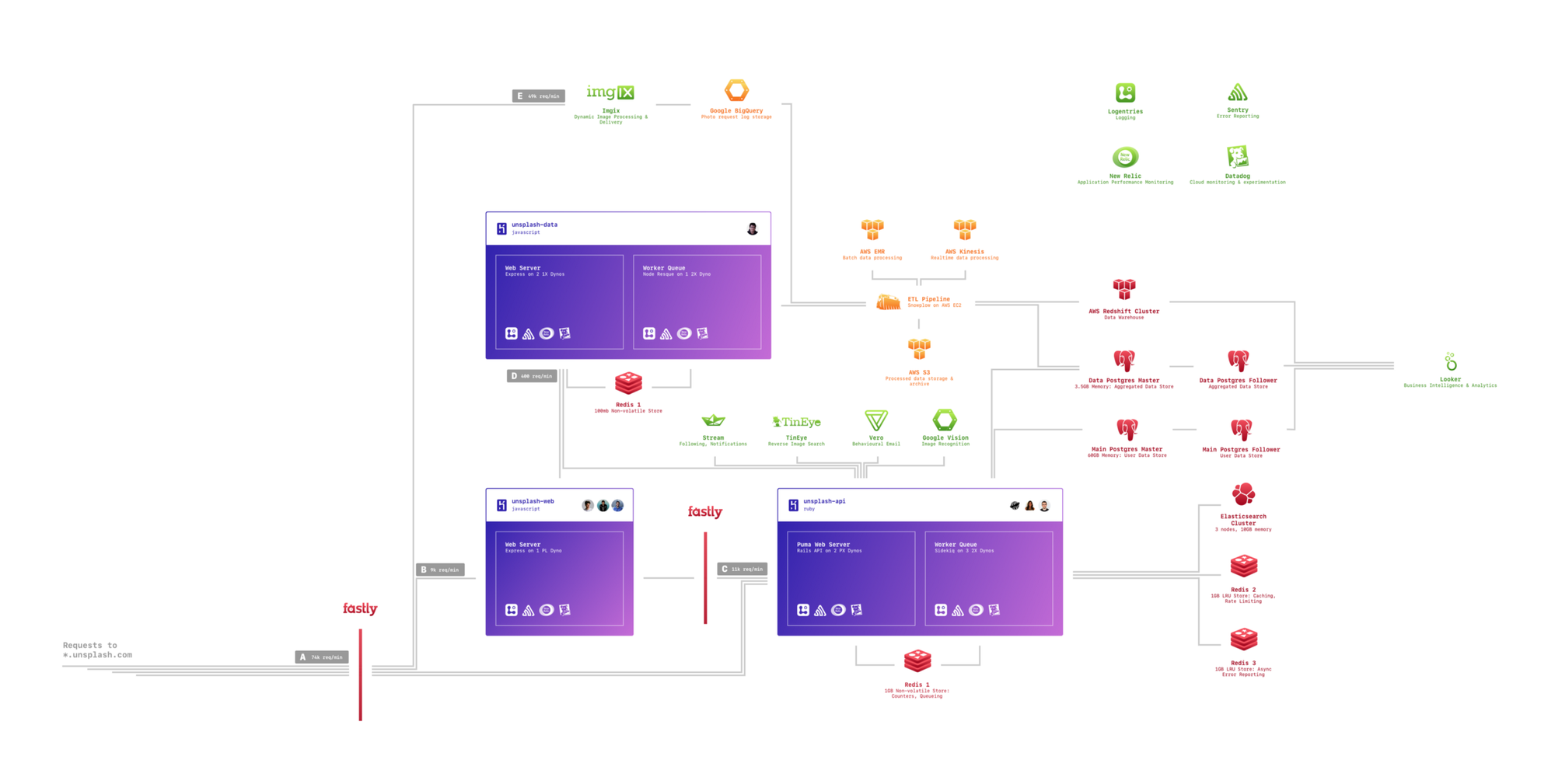
We use Heroku wherever we can to simplify deployment, configuration, testing, maintenance, and scaling of our primary applications. Heroku is magic since it abstracts away parts of the application and development process that no teammate should need to be familiar with to build and ship an experiment.
We aggressively minimize the code we write for the application logic (the purple areas). In the application logic, we lean heavily on frameworks built by other people, who have, by virtue of being experts in their areas, created a set of principles that should work for 95% of our use cases.
We lean heavily on Redis, ElasticSearch, and Postgres for all production loads. We’ve tried other databases in the past, but we’ve always gone back to these three, since we are confident in our understanding of how these databases operate under load.
We aggressively use worker queues, pushing as many operations into an asynchronous processing queue, whether it’s updating, aggregating, or syncing across resources.
Our data processing uses Snowplow, an open-source integrated data processing framework written in Scala, freeing our team to concern themselves with the input and output of the system, and not the actual processing.
We use an array of cloud monitoring services like Datadog, New Relic, Sentry, and Logentries, instead of trying to manage or roll our own StatsD or ELK stacks.
We outsource all of our image hosting and infrastructure to Imgix, the leading dynamic image processing company in the world. As they add industry-leading features, our team opts-in with a single URL change, delivering the latest in image optimizations and processing to our users.
We push all of our user activities to Stream, a feed aggregation service, leveraging their knowledge of building and optimizing highly-scalable personalized feeds. Stream simplifies processing billions of activities into a simple API for input and output, with performance that would take our team months, if not years, to learn and optimize.
We don’t train our own image recognition algorithms, and instead use TinEye for reverse image search and Google Vision for image understanding and classification.
We push all of our behavioural events to Vero, an email marketing and notification platform, that moves email engagement out of our apps and into the hands of our non-developer teammates, allowing them to build highly-personalized emails, based on complex event-based logic on their own insights.
At the same time, we do invest in the parts of Unsplash that align with enhancing our core competency.
Over the last year we’ve transitioned the app progressively from a single Rails application to a Rails API, a Node + React powered web app, and a separate data app that handles data collection and processing for all of our internal and product metrics.
Overall, this allows our team to build features that would have been near-impossible on our previous Rails-only stack. By splitting our application’s concerns and technologies our team are also able to use the best tools in each of their areas:
- On the frontend our team uses React and Webpack, with a small Express server to support server-side rendering and proxying the API. We very deliberately did not tie our frontend team’s tooling to our backend team with temporary hacks like react-rails or webpacker. The Javascript community is undoubtably producing the best frontend tooling, so working natively in Javascript allows our team to ship better quality features, quicker.
- On the backend, our team continues to use the best framework for a straightforward web app: Rails. The Rails ecosystem continues to produce the best integrated tooling for backend feature development, and with Rails being such a widely used framework, every possible issue has already been experienced, documented, and solved by other teams.
- On the data side, our team uses a small Express server to collect and queue data for processing. The actual data processing is handled by Snowplow, hosted on a set of AWS images, making for easy configuration and setup. This allows our single data engineer, Tim, to focus the majority of his time on feeding data into and out of Snowplow, in a way that makes for easy understanding and insights for the rest of the team.
We invest heavily in writing tests, measure performance using tools like Scientist and Datadog, roll out changes using experiments, and automate as much of our infrastructure as possible.
We’re developing a new internal GraphQL API to speed up independent iterations of experiments, new features, and new products, as we’ve found our RESTful API to break down without a high level of coordination between our data, design, frontend, and backend teams — time which would be better spent on features, not JSON changes.
While these changes have obviously been fun to work on, we don’t do them to scratch our itch as developers, but rather to solve real problems impeding our ability to iterate quickly and grow.
I think most people who read how Unsplash is built will probably have one of three reactions:
- Unsplash is simple, so obviously you can take this approach. What I’m building is complicated so we need to do those things.
- I’m a developer. That sounds really boring — I want to build the next highly scalable image recognition system!
- Cool 👍 I don’t care, just show me some amazing free photos I can use.
To people thinking #1, you’re right, there are obviously companies doing a lot more complicated things than what we’re doing at Unsplash. But at the end of the day, most companies simply aren’t. We’re all basically building the same systems but with a slightly different focus, which is why technologies can be abstracted to frameworks and reused across so many projects, and why most hiring posts look so damn similar.
To #2, I say it depends what you find interesting. If you’re interested in pushing the bounds of technology, then go work for a company who’s mission it is to do that. They are few and far between though, because at the end of the day, most companies simply aren’t doing that.
And to number #3, I say yes, that’s exactly right. In the end thats all we care about doing too!
If you have any questions, or want to dive deeper into this, give me a shout on Twitter @lukechesser. Also, if you find yourself nodding along and love building great experiences, we’re hiring at Unsplash 👉